When one thinks of a cowboy or a cowgirl, a Black person may not be the first image that comes to mind. Despite being erased from most history books, the legacy of the Black cowboy and cowgirl has a strong culture throughout the country, particularly the South.
One group is continuing its fight to preserve the heritage of these unsung heroes, even through the COVID-19 pandemic.
The Circle L Five Riding Club is the oldest Black riding club in Texas and a staple within the Fort Worth community for over 70 years. Founded in 1951, the founders wanted to create a club where they ccould keep their cowboy traditions alive during Jim Crow.
“They came up with the club name as they were sitting in a circle talking about organizing a riding club. [Ed] “Pop” Landers (one of the founders of the riding club) had a stick in his hand and made a circle in the dirt,” said Marcellous “Mo” Anderson, president of Circle L 5, in an email interview with BLACK ENTERPRISE.
“They decided on ‘Circle,’ and, as it was Lander’s idea, they used his last name’s initial ‘L.’ Since it was just the five of them, they came up with the name Circle L 5 Riding Club. ‘Pop’ Landers had the vision and desire to create the riding club’s existence because he wanted to be able to ride as a Black cowboy in any parade or rodeo he desired.”
Despite numerous attempts to derail the group, including an incident during the Fort Worth Stock Show during segregation where many of the riders faced discrimination from their White counterparts, the members are committed to preserving their culture while showing others in the Black community that riding horses and being a cowboy or cowgirl isn’t just in White culture.
“Black Cowboys go back to the very beginning of American cowboy history when groups of men on horseback would take months-long trail drives from their hometowns–usually in Texas, Oklahoma, Colorado, California, North Dakota, or South Dakota–to connect with Midwestern railroads, herding their cattle along the way,” Anderson explained.
“The journeys were long and dangerous, and whether you were Black, White, or Mexican, you slept in the same spaces, ate the same food, performed the same tasks, and took the same risks. Those who survived the journeys formed bonds that would last a lifetime.”
Although the spread of COVID-19 has canceled all club events for the rest of the year, Anderson says that still hasn’t deterred riders from spending time with their horses.
“Once we get down here, we wear our masks and social distance while taking care of our horses,” he says.
from Black Enterprise https://ift.tt/2RoBb22
via Gabe's Musing's
In this guide, we will discuss some of the popular rolling release distributions. If you are new to the concept of a rolling release, worry not. A rolling release system is a Linux distribution
On September 15th in New York, Sotheby’s will let buyers place bids on hip-hop memorabilia
Well-known international auction house Sotheby’s will pay tribute to Hip Hop next week with its first auction dedicated to the culture.
On September 15th in New York, Sotheby’s will let buyers place bids on hip-hop memorabilia, some items dating back to the 1970s.
One of the most iconic items up for auction is the crown worn by Brooklyn-born Biggie Smalls during the 1997 “King of New York” photo shoot. The portrait he took with that crown was his last before he was killed in Los Angeles three days later.
The auction will also feature more than 20 love letters written by a young, 16-year-old Tupac Shakur to his high school sweetheart.
“Since its birth in the Bronx in the 1970s, Hip Hop has become a global cultural force, whose massive influence continues to shape all realms of culture: music, fashion, design, art, film, social attitudes, language, and more,” Cassandra Hatton, Vice President & Senior Specialist in Sotheby’s Books and Manuscripts Dept. said.
“This sale is a celebration of the origins and early eras of that influence. We are pleased to announce the auction with two renowned and beloved icons whose lives and lyricism continue to resonate — Biggie and Tupac — with lots that offer an introspective look, in their own way, at the personalities behind their respective public personas.”
B.I.G.’S ‘KING OF NEW YORK’ CROWN
American rapper Notorious BIG (born Christopher Wallace) attends the 1995 Billboard Music Awards, New York, New York, December 6, 1996. (Photo by Larry Busacca/WireImage)
The crown was obtained by photographer Barron Claiborne, who has had it in his possession since the now renowned photoshoot. Included in this lot are three specially sized prints, signed by Claiborne, of the iconic ‘K.O.N.Y’ photograph, the 10th anniversary K.O.N.Y. photograph, and the contact sheet, which is estimated to sell around $200,000-$300,000. The interior of the crown is signed by both Biggie and Claiborne.
“I’m very excited to share this iconic piece of Hip Hop history with the public. With the tragic events that unfolded just days after the photoshoot, this image of a crowned Notorious B.I.G. became much more than a portrait – the image transformed Biggie Smalls into an aristocratic or saint like figure, forever immortalized as not only the King of New York, but a king of Hip Hop music and one of the greatest artists of all time, ” said Claiborne.
TUPAC SHAKUR’S TEENAGE LOVE LETTERS
Rapper Tupac Shakur poses for photos backstage after his performance at the Regal Theater in Chicago, Illinois in March 1994. (Photo By Raymond Boyd/Getty Images)
22 autographed love letters written by a 16-year-old Tupac Shakur to Kathy Loy, a high school sweetheart from the Baltimore School for the Arts are estimated to sell at around $60,000-$80,000. The lot includes 42 pages on 24 sheets of paper and one greeting card. Tupac signed all the letters.
Shakur would have been in the 10th grade when he wrote the letters. He and Loy took theater classes at the school. The letters span from late March 1987 to April 1988, from their meeting to an eventual breakup.
The letters even show Shakur’s close friendship with fellow student Jada Pinkett. In one letter he wrote “Jada told me she can see how much I love you…”
Shakur also wrote about his doubts about his music career. He wrote, “my old manager came over and said she doesn’t want me to retire from rap but I think I am because I can’t handle too much rejection and I don’t have the time…”
Shakur also admitted to fearing rejection and his lack of confidence, noting that “I just want to be less sensitive and less of a pest…. What I am feeling has to do with my insecurities, and I have to handle that on my own…”.
In the final letter, Tupac penned to ‘Ms. Loy’ nearly a year after the pair’s break up, Shakur shared how he has moved out of his mother’s home and sincerely expresses regret over their break-up.
.@Sothebys is set to host its first-ever hip-hop auction, headlined by Notorious B.I.G.'s 'King of New York' crown and love letters written by Tupac Shakur.
Overall, the sale will feature more than 120 pieces including: unique artifacts, contemporary art, one of a kind experiences, photography, vintage and modern fashion, historic and newly designed jewelry and luxury items, rare ephemera including flyers and posters, important publications, and more.
The majority of items in the sale have been consigned directly by artists or their estates and the full contents of the auction will be announced at a later date.
A portion of the proceeds will benefit the Queens Public Library Foundation, to support their Hip Hop Programs and also Building Beats, a non-profit organization that teaches tech, entrepreneurial and leadership skills to underserved youth through music programs.
Monica Lynch, former president of Tommy Boy Records (1981-1998), collaborated with Sotheby’s to organize the event. Lynch helped launch the careers of legends Afrika Bambaataa & Soulsonic Force, Queen Latifah, De La Soul, and Naughty by Nature, among many others.
Those interested in viewing the auction items in person will need to set up an appointment in Sotheby’s York Avenue galleries beforehand. Slots are open from September 11th– 15th. The public can also see the exhibition online.
Have you subscribed to theGrio’s podcast “Dear Culture”? Download our newest episodes now!
It’s been 20 years since the first movie premiered
Gabrielle Union confirmed a sequel to “Bring It On,” with the original cast, is in pre-production.
On The Late, Late Show With James Corden, Union told the host that she will reprise her starring role as Isis in the film. The movie will return to the big screen and will also feature Kirsten Dunst.
“I think [we agreed] because we all got obsessed with Cheer on Netflix and it kind of like brought back the whole love of cheerleading, and we kinda want to see where these people would be 20 years later,” Union said.
Cheer on Netflix is a docuseries that focuses on five individual cheer team members, the history of cheerleading, the formation of the National Cheerleaders Association, and the inner workings of modern cheerleading.
PopSugar reported this future installment of “Bring It On” will be the first sequel to feature the original cast.
It has been 20 years since the release of the original movie, which spawned five direct-to-video sequels and a Broadway musical. The latest film in the series was released in 2017, and it was called “Bring It On: Worldwide #Cheersmack.”
As Huffington Post reporter Emma Gray said, “this docu-series is a riveting, heartfelt peek into the world of elite collegiate cheerleading, something that I admit I knew painfully little about outside of fictional depictions like ‘Bring It On.’”
The hit 2000 movie has not only propelled the careers of the actors but paved the pathway for similar teen flicks involving cheerleading and competitive dance, such as “Fired Up!.”
Union, 47, has been active in several roles on TV and film. She is currently on Fox’s L.A.’s Finest as Special Agent Sydney “Syd” Burnett alongside co-star Jessica Alba for the second season.
Have you subscribed to theGrio’s podcast “Dear Culture”? Download our newest episodes now!
As its name suggests, searching for videos by image is the process of retrieving from the repository videos containing similar frames to the input image. One of the key steps is to turn videos into embeddings, which is to say, extract the key frames and convert their features to vectors. Now, some curious readers might wonder what the difference is between searching for video by image and searching for an image by image? In fact, searching for the key frames in videos is equivalent to searching for an image by image.
The following diagram illustrates the typical workflow of such a video search system.
When importing videos, we use the OpenCV library to cut each video into frames, extract vectors of the key frames using image feature extraction model VGG, and then insert the extracted vectors (embeddings) into Milvus. We use Minio for storing the original videos and Redis for storing correlations between videos and vectors.
When searching for videos, we use the same VGG model to convert the input image into a feature vector and insert it into Milvus to find vectors with the most similarity. Then, the system retrieves the corresponding videos from Minio on its interface according to the correlations in Redis.
2. Data preparation
In this article, we use about 100,000 GIF files from Tumblr as a sample dataset in building an end-to-end solution for searching for video. You can use your own video repositories.
3. Deployment
The code for building the video retrieval system in this article is onGitHub.
Step 1: Build Docker images.
The video retrieval system requires Milvus v0.7.1 docker, Redis docker, Minio docker, the front-end interface docker, and the back-end API docker. You need to build the front-end interface docker and the back-end API docker by yourself, while you can pull the other three dockers directly from Docker Hub.
# Build front-end interface docker and api docker images $ cd search-video-demo & make all
Step 2: Configure the environment.
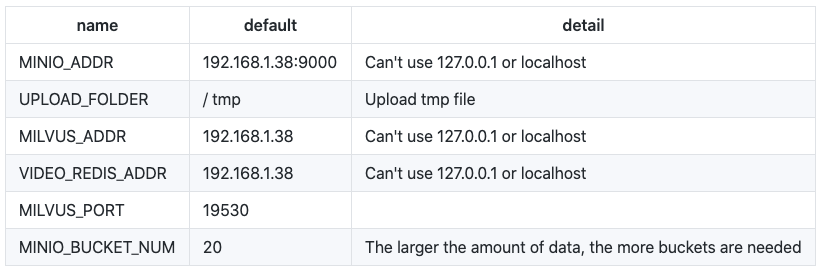
Here we usedocker-compose.ymlto manage the above-mentioned five containers. See the following table for the configuration ofdocker-compose.yml:
The IP address 192.168.1.38 in the table above is the server address especially for building the video retrieval system in this article. You need to update it to your server address.
You need to manually create storage directories for Milvus, Redis, and Minio, and then add the corresponding paths indocker-compose.yml. In this example, we created the following directories:
/mnt/redis/data /mnt/minio/data /mnt/milvus/db
You can configure Milvus, Redis, and Minio indocker-compose.ymlas follows:
Step 3: Start the system.
Use the modifieddocker-compose.ymlto start up the five docker containers to be used in the video retrieval system:
$ docker-compose up -d
Then, you can run docker-compose ps to check whether the five docker containers have started up properly. The following screenshot shows a typical interface after a successful startup.
Now, you have successfully built a video search system, though the database has no videos.
Step 4: Import videos.
In thedeploydirectory of the system repository, liesimport_data.py, script for importing videos. You only need to update the path to the video files and the importing interval to run the script.
data_path: The path to the videos to import.
time.sleep(0.5): The interval at which the system imports videos. The server that we use to build the video search system has 96 CPU cores. Therefore, it is recommended to set the interval to 0.5 second. Set the interval to a greater value if your server has fewer CPU cores. Otherwise, the importing process will put a burden on the CPU, and create zombie processes.
Runimport_data.pyto import videos.
$ cd deploy $ python3 import_data.py
Once the videos are imported, you are all set with your own video search system!
4. Interface display
Open your browser and enter 192.168.1.38:8001 to see the interface of the video search system as shown below.
Toggle the gear switch in the top right to view all videos in the repository.
Click on the upload box on the top left to input a target image. As shown below, the system returns videos containing the most similar frames.
Next, have fun with our video search system!
5. Build your own
In this article, we used Milvus to build a system for searching for videos by images. This exemplifies the application of Milvus in unstructured data processing.
Milvus is compatible with multiple deep learning frameworks, and it makes possible searches in milliseconds for vectors at the scale of billions. Feel free to take Milvus with you to more AI scenarios:https://github.com/milvus-io/milvus.
from Featured Blog Posts - Data Science Central https://ift.tt/2ZAyNd0
via Gabe's MusingsGabe's Musings
Machine Learning (ML) models are designed for defined business goals. ML model productionizing refers to hosting, scaling, and running an ML Model on top of relevant datasets. ML models in production also need to be resilient and flexible for future changes and feedback. A recent study by Forrester states that improving customer experience, improving profitability & revenue growth as the key goals organizations plan to achieve specifically using ML initiatives.
Though gaining worldwide acclaim, ML models are hard to be translated into active business gains. A plethora of engineering, data, and business concerns become bottlenecks while handling live data and putting ML models into production. As per our poll, 43% of people said they get roadblocked in ML model production and integration. It is important to ensure that ML models deliver their end objectives as intended by businesses as their adoption across organizations globally is increasing at an unprecedented rate, thanks to robust and inexpensive open-source infrastructure. Gartner predicts that over 40% of the world’s leading organizations plan to actually deploy AI solutions by the end of 2020. In order to understand the common pitfalls in productionizing ML models, let’s dive into the top 5 challenges that organizations face.
1. Complexities with Data
One would need about a million relevant records to train an ML model on top of the data. And it cannot be just any data. Data feasibility and predictability risks jump into the picture. Assessing if we have relevant data sets and do we get them fast enough to do predictions on top isn’t straightforward. Getting contextual data is also a problem. In one of Sigmoid’s ML scaling with Yum Brands, some of the company’s products like KFC (with a new royalty program) didn’t have enough customer data. Having data isn’t enough either. Most ML teams start with a non-data-lake approach and train ML models on top of their traditional data warehouses. With traditional data systems, data scientists often spend 80% of their time in cleaning and managing data rather than training models. A strong governance system and data cataloging are also required so that data is shared transparently and gets cataloged well to be leveraged again. Due to the data complexity, the cost of maintaining and running an ML model relative to the return diminishes over time.
2. Engineering and Deployment
Once the data is available, the infrastructure and technical stacks have to be finalized as per the use case and future resilience. ML systems can be quite difficult to engineer. A wide breadth of technology is available in the machine learning space. Standardizing different technology stacks in different areas while choosing each one such that it wouldn’t make productionizing harder is crucial for the model’s success. For instance, Data scientists may use tools like Pandas and code in Python. But these don’t necessarily translate well to a production environment where Spark or Pyspark is more desirable. Improperly engineered technical solutions can cost quite a bit. And then the lifecycle challenges and managing and stabilizing multiple models in production can become unwieldy too.
3. Integration Risks
A scalable production environment that is well integrated with different datasets and modeling technologies is crucial for the ML model to be successful. Integrating different teams and operational systems is always challenging. Complicated codebases have to made into well-structured systems ready to be pushed into production. In the absence of a standardized process to take a model to production, the team can get stuck at any stage. Workflow automation is necessary for different teams to integrate into the workflow system and test. If the model isn’t tested at the right stage, the entire ecosystem would have to be fixed at the end. Technology stacks have to be standardized else integration could be a real nightmare. Integration is also a crucial time to make sure that the Machine Learning experimentation framework isn’t a one-time wonder. Else if the business environment changes or during a catastrophic event, the model would cease to provide value.
4. Testing and Model Sustenance
Testing machine learning models is difficult but is as important, if not more, as other steps of the production process. Understanding results, running health checks, monitoring model performance, watching out for data anomalies, and retraining the model together close the entire productionizing cycle. Even after running the tests, a proper machine learning lifecycle management tool might be needed to watch out for issues that are invisible in tests.
5. Assigning Roles and Communication
Maintaining transparent communication across data science, data engineering, DevOps, and other relevant teams is pivotal to ML models’ success. But assigning roles, giving detailed access, and monitoring for every team is complex. Strong collaboration and an overdose of communication are essential to identify risk across different areas at an early stage. Keeping data scientists deeply involved can also decide the future of the ML model.
In addition to the above challenges, unforeseen events such as the COVID-19 have to be watched out for. When the customer’s buying behaviors suddenly change, the solutions from the past cease to apply and the absence of new data to adequately train models becomes a roadblock. Scaling ML models isn’t easy. Watch out for our next piece on the best practices to productionize ML models at scale.
Data science is a collective pool of various algorithms, tools, machine learning principles that work in unison to extract hidden patterns from raw data. It requires a diverse set of skills and demands knowledge from aspects of mathematics, science, communication, and business. Honing a diverse skill set, data scientists gain the ability to analyze numbers and influence decisions.
The core objective of data scientists lay in bridging the gap between numbers and actions by using information to affect real world decisions. This demands excellent communication skills along with understanding the difference between data science and big data analysis and recommendations to businesses.
DATA VISUALIZATION
Probably a major responsibility of a data scientist is to make data as presentable as possible for users to get better insights of raw data and to derive the desired information out of it. Visualizations are important in the first place because they guide the thought process of people viewing it for further analysis. They are used to create impactful data stories that communicate an entire set of information in a systematic format so that the audiences are able to extract meaning out of it and detect problem areas in order to propose solutions.
Without data visualization tools, it would be practically impossible to implement change or cater to the desired problems. Today, there are many data visualization tools to select from. In most of the programming languages, you’ll find libraries that enable visualization of data. In JavaScript, data can be visualized using the D3.js visualization library, Python uses Matplotlib and pandas while R offers many data visualization tools including ggplot2.
Tableau is the most trending, high-level platform that offers amazing data visualization options extracting data from many different sources.
DATA WRANGLING
Often the data comes from a variety of sources and needs remodelling to be able to derive informational insights. It is important to make the data free from imperfections such as inconsistent formatting, missing values etc. Data wrangling allows you bring the data on a uniform level that can be further processed easily. Obviously, for a data scientist to use data to their best, it is important to possess the knowledge of organizing clean data from the unmanageable raw data.
PROGRAMMING LANGUAGES & SOFTWARE
Data scientists deal with raw data that comes from a variety of sources and in different formats. Such data is filled with misspellings, duplications, misinformation and incorrect formats that can mislead your results. To correctly present the data, it is important to extract the data, clean it, analyze and visualize it. Below are six broadly used tools that are recommended strongly for data scientists:
R:R is a programming language that is widely used for data visualization, statistical analysis and predictive modelling. It has been around since many years and has been contributing largely to data analysts with its huge network (CRAN) that provides a complete package to allow analysts to perform various data-related tasks.
Python:Python initially was not looked upon as a data analytics tool. The pandas python library enables vectorized processing operations and efficient data storage. This high-level programming language is fast, user-friendly, easy to learn and powerful. It has been used for general programming purposes for long now and therefore allows easy merger of general-purpose code and Python data processing.
Tableau:Lately emerged as an amazing data visualization tool, Tableau, a Seattle-based software company offers an exclusive suite of high-end products that surpass the science resources such as R and Python. Although Tableau lacks the ultimate efficiency in reshaping and cleaning data and doesn’t provide options for procedural computations or offline algorithms, it is increasingly becoming a popular tool for data analysis and visualizations due to its highly interactive interface and efficiency in creating beautiful, dynamic dashboards.
SQL:Structured Query Language (SQL) is a special purpose programming language that allows for extracting and curing data that is held in relational database management systems. SQL allows users to write queries, insert data, update, modify and delete data. Though all of these can also be done using R and Python, writing an SQL code derives more efficient output and provides reproducible scripts.
Hadoop:Hadoop, an open source software framework fosters distributed processing of large amounts of data sets using simple algorithms from large clusters of computers. Hadoop is largely used in industries due to its immense computing power, fault tolerance, flexibility and scalability. It enables programming models such as MapReduce that enables processing of vast amounts of data.
STATISTICS
Though there are many automated statistical tests embedded within software, a data scientist needs to possess a rational statistical sensibility to apply the most relevant test for performing result-oriented interpretations. A solid knowledge of linear algebra and multivariable calculus assist data scientists in building analysis routines as needed.
Data scientists are expected to understand linear regression, exponential and logarithmic relationships while also knowing how to use complex techniques such as neural networks. Most of the statistical functions are done by computers in minutes, however, understanding the basics is essential in order to extract the full potential. A major task of data scientists lay in deriving the desired output from computers and this can be done by posing right questions and learning how to make computers answer them. Computer science is backed in many ways by mathematics and therefore data scientists need to have a clear understanding of mathematical functions to be able to efficiently write codes to make computers do their job perfectly.
ARTIFICIAL INTELLIGENCE & MACHINE LEARNING
AI is the most trending topics today. It empowers machines by providing intelligence in the real sense to minimize manual intervention to extreme levels. Machine learning works on algorithms that are automated to obtain rules and analyse data and is largely used in search engine optimizations, data mining, medical diagnosis, market analysis and many other areas. Understanding the concepts of AI & Machine learning for beginners play a vital role in learning industry needs and therefore are at the forefront of data science skills that a data scientist must possess.
MICROSOFT EXCEL
Even before any of the modern data analysis tools existed, MS-Excel had been there. It is probably the oldest and most popular data tools.
Although now there are multiple options to replace MS-Excel, it has been proven that Excel offers some really surprising benefits over others. It allows you to name & create ranges, sort/filter/manage data, create pivot charts, clean data and look up for certain data among millions of records. So, even though you might feel that MS-Excel is outdated, let me tell you it is absolutely not. Non-technical people still prefer using Excel as their only source of storing and managing data. It is an important pre-requisite for data scientists to have an in-depth understanding of Microsoft Excel to be able to connect to the data source and efficiently pick data in the desired format.
from Featured Blog Posts - Data Science Central https://ift.tt/32mPMRQ
via Gabe's MusingsGabe's Musings
I recently wrote about a stock trading approach that I call skipjack: it allows the user to trade directly from special charts by exploiting skipjack waveforms and formations. I mentioned that I use an application - a simulation environment - to trade from these charts. Below I present a screenshot of SimTactics, the application that I created to support this simulated trading. To the right is a notepad containing four trades generated by an autopilot feature of the SimTactics. Over the time period, the Nasdaq Composite increased 41.72 percent. SimTactics squeezed out 61.44 percent before closing out its position at the end of the data file. SimTactics makes use of a risk-based index constructed from the same waveforms that support skipjack stock trading.
The main problem with manual stock trading is that it requires a lot of effort. Because a human is involved, the results might be inconsistent. Also, markets move quickly - perhaps faster than the skipjack trading model can handle well. I have shown however how manual trading can sometimes deliver relatively high returns over short time periods. It is a perspective worth maintaining. But in this blog, I will be introducing the use of Thunderbird Charts to study algomorphology. This technique supports a different type of trading.
SimTactics uses combinations of buy-and-sell percentages to respond a "trigger package." This package is made up of the Levi-Tate group of technical metrics that I designed for skipjack. For example, a snap buy-and-sell combination of 23/24 means that SimTactics buys at a risk level of 23 percent or below and sells at 24 percent or above. Now, if a matrix is created to study many possible combinations, the result is a Thunderbird Chart as shown below. This chart contains data in the year prior to the stock market crash of October 1987 for the Dow Jones Industrial Average.
Any combination in the deep purple area would have resulted in a 30 to 40 percent return. But wait, how about the crash? Indeed, let use step back and consider the period before, during, and after the crash. Suddenly, the returns are much lower. This only tells us that the best place to be during a crash is not in the stock market. However, it is no simple matter simply sitting on large amounts of cash particularly for portfolio managers. Even for retail investors, it is unclear how long precisely to avoid the market. Avoidance also represents loss of opportunity. The light green area below experienced returns from 20 to 40 percent - significantly above the market return of 5.44 percent during the same period.
There is some level of overlap in terms of optimal positioning. The chart below shows that best-performing combinations occupied a thin band on the Thunderbird Chart. It is a curious sweet spot well worth further investigation.
If it is possible to buy a market-indexed ETF rather than individual stock, personally I would avoid the uncertainty posed by selection. However, everyone is different. The stock below increased about 11.79 percent. The chance of beating market is reasonably good within the deep purple area - keeping in mind that I can refer to the spreadsheet grid. Then there is quite literally a sweet spot in an unorthodox location that I myself would never deliberately choose. Why? Well, optimum - or maybe I should call it optimus after the transformer - is in motion. The spot will likely move in the future. At the same time, the whole idea of studying algomorphology to ascertain what underlying phenomena bring about the quantitative outcomes
So far given these charts, I suspect readers have a sense of "normal" versus "abnormal" tactical placement. But I will be studying the point in greater detail - examining different investments under changing market conditions and cycles. I know that this is an interesting way to think about investments and algorithms.
from Featured Blog Posts - Data Science Central https://ift.tt/2FqGzih
via Gabe's MusingsGabe's Musings
I was asked this question: What is the connection between AI, Cloud-Native and Edge devices?
On first impressions, it sounds like an amalgamation of every conceivable buzzword around - but I think there is a coherent answer which points to a business need.
Let us start with the term ‘Cloud Native.’
Cloud-native computing is an approach in software development that utilizes cloud computing technologies such as
Containers
Microservices
Continuous Delivery
DevOps
Using Cloud Native technologies, we can create loosely coupled systems that are scalable and resilient.
In practice, this means
a) The system is built as a set a set of microservices that run in Docker containers
b) The containers may be orchestrated via Kubernetes
c) The deployment is managed through docker containers through a CI/CD process
In itself, this approach is valuable and follows a stack that is rapidly emerging at the Enterprise level.
But how does it tie to Edge devices?
Docker allows you to create a single packaged deployment through a container, which creates a virtualized environment at the target device. AI models are trained in the cloud and deployed on edge devices. The docker/ cloud-native format enables you to run AI in containers across various environments, including at the Edge. The container-based architecture is especially relevant for AI on edge devices because of the diversity of devices.
Secondly, AI models need to be refreshed and deployed frequently – including on edge devices. For this reason, also, the cloud-native and container architecture helps.
In an episode of Inside The NBA, after a close game between Los Angelos Lakers and Houston Rockets, he was spotted with durag, which made Barkley asked why.
“Did LeBron have a drag on?” Barkley said. “He don’t have enough hair for that to do anything.”
This is not the first time Barkley and company made of receding hairline.
On February 02, 2012, co-hosts Shaq, Kenny Smith, and Ernie Johnson Jr. along with Barkley mocked the star player’s hairline prior.
“Come on home, brah. Shave your head.” Barkley, who is bald said. Barkley then sported a headband, impersonating James’ balding like head.
“LeBron James started the NBA like this,” Barkley said wearing the band as one would normally wear it.
“Now, it is like this,” Barkley said as he then shifted the band irregularly to demonstrate how James’ hairline was moving away from his forehead as he became more established in the league.
James is a good sport about his depeting hair, and later followed up that episode by calling Shaq, Kenny, and Barkley “three bald-headed stooges” on the TNT program.
Although James’ hair has improved since the interview, James continues to mock himself from time to time.
Young 🤴🏾 on a mission and haven’t stopped! P.S. Can’t believe my hair decided to go Casper on me like this though. “Ghost” 🤦🏾♂️. 🤣🤣🤣🤣🤷🏾♂️ https://t.co/NTT5rwiBr1
“One if the funniest [memes] I’ve seen. Hated when my Reese cup would do that but guess what I still kept it and ate it so 🤷🏽♂️😁”
– LeBron/IG Story pic.twitter.com/oGWEElWxP6
Osaka humbly shared how the win against Victoria Azarenka was a full-circle moment for her
Naomi Osaka beat Belarusian tennis player Victoria Azarenka in Saturday’s U.S. Open final in New York to win her third Grand Slam title.
“First I want congratulate Vika,” The 22-year-old said after completing the match. “I actually don’t want to play you in any more finals. I didn’t really enjoy that. It was a really tough match for me.”
Naomi Osaka of Japan celebrates with the trophy after winning her Women’s Singles final match against Victoria Azarenka of Belarus on Day Thirteen of the 2020 US Open at the USTA Billie Jean King National Tennis Center on September 12, 2020 in the Queens borough of New York City. (Photo by Matthew Stockman/Getty Images)
Osaka is the first woman in 26 years to win a U.S. Open final after losing the opening set. Even Lebron James sent a congrats to the young tennis star.
“It’s really inspiring for me because I used to watch you play here when I was younger. So just to have the opportunity to play you is really great and I learned a lot, so thank you, ” Osaka said.
After the match a reporter asked Osaka about her decision to wear seven different masks bearing the names of high-profile victims of police violence.
“What was the message that you got?” she said. “The point is to make people start talking.”
“For me, I’ve been inside of the bubble so I’m not really sure what’s really going on in the outside world. All I can tell is what’s going on on social media and for me I feel like the more retweets it gets – that’s so lame but … the more people talk about it.”
The coronavirus pandemic caused this event, like many other professional sports, to be played without fans. However her boyfriend, rapper Cordae cheered her on from the stands, while wearing a “defund the police” t-shirt. He jumped up with excitement when she took the victory.
Two weeks prior, Osaka and Azarenka were scheduled to play in the Western & Southern Open final, but Osaka withdrew due to her injury.
The Women’s Tennis Association ranks Osaka No. 1 and she is the first Asian player to hold the top ranking in singles. She holds an undefeated 3-0 career record in the major finals.
Have you subscribed to theGrio’s podcast “Dear Culture”? Download our newest episodes now!
The late Glee star’s body was found in California’s Lake Piru in July after being reported missing five days prior
The autopsy report of Naya Rivera, whose body was found in a California lake in July, was released on Friday.
Rivera had been swimming in the lake with her three-year-old son, Josey Dorsey, after renting a pontoon boat when she drowned. The autopsy report said, before drowning, that she had lifted Dorsey into the pontoon, raised her arm and yelled for help before being submerged, as reported by Associated Press.
The late Glee star’s body was found in California’s Lake Piru on July 14 after being reported missing five days prior.
Actress Naya Rivera poses for a portrait session at Giffoni Film Festival in Giffoni Valle Piana, Italy. (Photo by Vittorio Zunino Celotto/Getty Images)
The Ventura County Medical Examiner stated that Josey “noticed the decedent put her arm up in the air and yelled ‘help,'” before Rivera “disappeared in to the water.”
Rivera was last seen alive when she took Josey to rent the pontoon boat to venture into the lake. The rental staff stated he gave her a single life jacket, despite the fact she declined one initially.
A search was conducted for Rivera when the boat was discovered on the lake with Josey found sleeping inside with the life jacket on. Her body was found floating atop the lake, and authorities believe her body was previously stuck in the lake’s thick vegetation under the surface.
A toxicology report indicated that Rivera had small amounts of diazepam, an anti-anxiety medication, and phentermine, an appetite suppressant, in her blood. The report said it was a therapeutic amount in her system.
The autopsy also stated that Rivera had prior bouts of vertigo as well.
Naya Rivera and Josey Dorsey (Instagram)
After being found in the boat, Josey was taken to his father, Rivera’s ex-husband Ryan Dorsey.
Rivera was 33 at the time of her death, and is the third actor from the Fox show, Glee, to pass away.
Actors Mark Salling, a former boyfriend of Rivera, and Cory Monteith died by suicide in 2018 and drug overdose in 2013, respectively, while in their 30s.
Have you subscribed to theGrio’s podcast “Dear Culture”? Download our newest episodes now!